Ever wondered why your server slows down or your app crashes unexpectedly? A reliable system monitor could be the silent hero you’re missing. Let’s dive into how real-time insights can transform your IT operations.


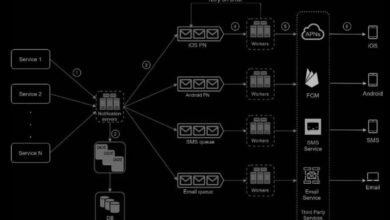
What Is a System Monitor and Why It Matters

A system monitor is a software tool designed to track, analyze, and report on the performance and health of computer systems, networks, and applications. It plays a crucial role in maintaining uptime, optimizing resources, and preventing costly outages. In today’s digital-first world, where milliseconds matter, having a robust system monitor isn’t optional—it’s essential.
Core Functions of a System Monitor
At its heart, a system monitor performs several key functions that ensure your infrastructure runs smoothly. These include tracking CPU usage, memory consumption, disk I/O, network latency, and process activity. By continuously collecting this data, it provides administrators with a real-time view of system behavior.
- Real-time performance tracking
- Alerting on anomalies or threshold breaches
- Historical data logging for trend analysis
These capabilities allow teams to detect issues before they escalate, such as a memory leak consuming RAM over time or a rogue process hogging CPU cycles.
Types of System Monitoring
Not all monitoring is created equal. Depending on your environment, you might need different types of system monitor approaches:
- Hardware Monitoring: Tracks physical components like temperature, fan speed, and power supply status.
- Software Monitoring: Focuses on application performance, service availability, and process health.
- Network Monitoring: Observes bandwidth usage, packet loss, and connection latency across devices.
Modern system monitor solutions often combine these types into a unified platform, giving a holistic view of your entire IT ecosystem. For example, tools like Nagios offer comprehensive monitoring across servers, switches, and applications.
Top 7 System Monitor Tools You Should Know
Choosing the right system monitor can make or break your operational efficiency. Below is a curated list of seven powerful tools—each with unique strengths—that dominate the market in 2024.
1. Nagios XI – The Veteran Powerhouse
Nagios XI has been a staple in system monitoring for over two decades. Known for its flexibility and extensive plugin ecosystem, it supports everything from Linux servers to cloud environments.
- Highly customizable dashboards
- Supports thousands of plugins via Nagios Exchange
- Enterprise-grade alerting and reporting
While its interface may feel dated compared to newer tools, its reliability and community support remain unmatched. Learn more at Nagios XI Official Site.
2. Zabbix – Open Source with Enterprise Muscle
Zabbix stands out as one of the most feature-rich open-source system monitor platforms. It offers auto-discovery, web monitoring, and deep integration with cloud providers like AWS and Azure.
- Real-time problem detection using AI-based anomaly detection
- Scalable from small businesses to large enterprises
- Built-in visualization tools and templated configurations
Its active community and commercial support options make Zabbix a top contender. Visit Zabbix.com to explore its full potential.
3. Datadog – Cloud-Native Champion
Datadog excels in dynamic, cloud-heavy environments. As a SaaS-based system monitor, it integrates seamlessly with Kubernetes, Docker, AWS, and hundreds of other services.
- Unified observability across metrics, logs, and traces
- AI-powered alerting and incident management
- User-friendly interface with drag-and-drop dashboards
Datadog’s strength lies in its ecosystem. With over 600 integrations, it’s ideal for DevOps teams needing end-to-end visibility. Check it out at DatadogHQ.com.
4. Prometheus – The Scalable Time-Series Titan
Prometheus is a favorite among developers and SREs working in microservices architectures. Originally developed at SoundCloud, it’s now a CNCF (Cloud Native Computing Foundation) project.
- Pull-based model for collecting metrics
- Powerful query language (PromQL)
- Excellent for Kubernetes and containerized workloads
While it lacks built-in visualization (often paired with Grafana), its scalability and precision make it a go-to system monitor for high-performance environments. Learn more at Prometheus.io.
5. PRTG Network Monitor – All-in-One Simplicity
Developed by Paessler, PRTG is known for its ease of setup and intuitive interface. It uses sensors to monitor various aspects of your network and systems.
- Auto-discovery of network devices
- Over 200 sensor types (SNMP, Ping, NetFlow, etc.)
- Free version available for up to 100 sensors
PRTG is perfect for SMBs or IT teams without dedicated DevOps staff. Its Windows-based installation makes deployment straightforward. Explore it at Paessler.com/PRTG.
6. New Relic – Full-Stack Observability Leader
New Relic provides deep insights into application performance (APM), infrastructure, and user experience—all from a single platform.
- Real-time code-level diagnostics
- Browser and mobile monitoring
- Customizable dashboards and alerting
Its AI-driven tool, New Relic AI, helps reduce mean time to resolution (MTTR) by automatically correlating events. Ideal for organizations practicing continuous delivery. Visit NewRelic.com for a free trial.
7. SolarWinds Server & Application Monitor (SAM)
SolarWinds SAM is a comprehensive solution for monitoring both physical and virtual servers, along with critical applications like SQL, Exchange, and SAP.
- Pre-built templates for common applications
- Deep performance analytics and capacity planning
- Integration with Orion Platform for extended monitoring
Despite past security concerns, SolarWinds has rebuilt trust with enhanced security protocols. It remains a strong choice for enterprise IT teams. Learn more at SolarWinds.com/SAM.
Key Metrics Tracked by a System Monitor
To truly understand system health, a system monitor must track specific performance indicators. These metrics form the foundation of proactive maintenance and capacity planning.
CPU Usage and Load Average
CPU utilization indicates how much processing power is being used. Consistently high CPU usage (above 80%) can signal performance bottlenecks.
- Load average shows the number of processes waiting for CPU time over 1, 5, and 15 minutes
- Sudden spikes may indicate inefficient code or denial-of-service attacks
- Long-term trends help in forecasting hardware upgrades
A good system monitor will alert when thresholds are exceeded and provide historical graphs for analysis.
Memory Utilization and Swap Activity
Memory (RAM) monitoring is critical for application responsiveness. When RAM is exhausted, systems start using swap space on disk, which is significantly slower.
- Track free vs. used memory, including cache and buffers
- Monitor swap usage—high swap activity indicates memory pressure
- Detect memory leaks in long-running applications
Tools like Zabbix and Datadog can break down memory usage by process, helping pinpoint resource hogs.
Disk I/O and Storage Health
Disk performance directly affects application speed, especially for databases and file servers.
- Monitor read/write latency, throughput (MB/s), and IOPS
- Track disk queue length—long queues mean storage bottlenecks
- Watch for SMART errors on physical drives
System monitor tools like PRTG and Nagios can send alerts when disk space falls below a certain percentage, preventing outages due to full disks.
Network Performance Metrics
Network issues are often the hidden cause of poor application performance.
- Bandwidth utilization: identify congestion points
- Packet loss and retransmissions: signs of network instability
- Latency and jitter: crucial for VoIP and real-time apps
Using SNMP or NetFlow, a system monitor can map traffic patterns and detect unauthorized devices on the network.
“You can’t manage what you can’t measure.” – Peter Drucker. A system monitor turns abstract system behavior into measurable, actionable data.
How to Choose the Right System Monitor for Your Needs
Selecting the best system monitor depends on your environment, team size, budget, and technical requirements. Here’s a structured approach to help you decide.
Assess Your Infrastructure Complexity
Start by mapping your IT landscape:
- Are you running on-premises servers, cloud VMs, or containers?
- Do you use hybrid or multi-cloud setups?
- How many devices and services need monitoring?
For simple setups, PRTG or Zabbix might suffice. For complex, distributed systems, consider Datadog or New Relic.
Evaluate Scalability and Performance
Your system monitor should grow with your infrastructure.
- Can it handle thousands of metrics per second?
- Does it support clustering or distributed collectors?
- What’s the data retention policy?
Prometheus, for example, is highly scalable but requires external storage (like Thanos) for long-term retention.
Consider Integration and Ecosystem
A tool that doesn’t integrate with your existing stack creates silos.
- Check compatibility with CI/CD pipelines (Jenkins, GitLab)
- Look for Slack, Teams, or PagerDuty alert integrations
- Ensure API access for automation and custom dashboards
Datadog and New Relic lead here, offering extensive APIs and pre-built integrations.
Best Practices for Effective System Monitoring
Even the best system monitor tool will underperform without proper strategy. Follow these best practices to maximize ROI.
Define Clear Monitoring Objectives
Start with business goals: Are you aiming for 99.99% uptime? Faster incident response? Better user experience?
- Map technical metrics to business outcomes
- Prioritize monitoring for critical services (e.g., payment gateways)
- Avoid “monitoring everything” – focus on what matters
Clarity here prevents alert fatigue and wasted resources.
Set Smart Alert Thresholds
Too many alerts lead to ignored notifications. Too few mean missed issues.
- Use dynamic thresholds based on historical baselines
- Implement alert deduplication and escalation policies
- Leverage AI/ML for anomaly detection (e.g., Datadog’s Watchdog)
A well-tuned system monitor alerts only when action is needed.
Automate Response and Remediation
Go beyond detection—enable automatic fixes.
- Trigger scripts to restart failed services
- Scale cloud instances based on load
- Integrate with ticketing systems like Jira
Automation reduces downtime and frees up IT staff for strategic work.
The Role of AI and Machine Learning in Modern System Monitoring
Traditional threshold-based alerts are giving way to intelligent, predictive monitoring powered by AI.
Anomaly Detection and Baseline Learning
AI-driven system monitors learn normal behavior over time and flag deviations.
- No need to manually set thresholds
- Adapts to seasonal traffic patterns (e.g., Black Friday spikes)
- Reduces false positives by understanding context
Datadog’s Dynamic Baselines and New Relic’s AI Ops are prime examples of this shift.
Predictive Failure Analysis
By analyzing trends, AI can predict hardware failures before they happen.
- Forecast disk failure using SMART data and wear patterns
- Predict memory exhaustion based on usage trends
- Alert on potential network congestion before it impacts users
This proactive approach transforms IT from reactive firefighting to strategic planning.
Root Cause Analysis and Event Correlation
When an outage occurs, AI can sift through millions of logs and metrics to find the root cause.
- Correlate events across services and layers
- Identify cascading failures in microservices
- Generate incident summaries for faster resolution
Tools like Splunk IT Service Intelligence (ITSI) use machine learning to map dependencies and isolate issues.
Common Challenges in System Monitoring and How to Overcome Them
Even with advanced tools, teams face recurring challenges in system monitoring.
Alert Fatigue and Noise
Receiving hundreds of alerts daily desensitizes teams, leading to missed critical issues.
- Solution: Implement alert grouping, suppression, and prioritization
- Use severity levels (Critical, Warning, Info)
- Integrate with incident management platforms like Opsgenie
A clean, actionable alert stream is key to effective monitoring.
Data Overload and Visualization Issues
Collecting too much data without proper visualization leads to confusion.
- Solution: Use dashboards tailored to different roles (e.g., exec, ops, dev)
- Leverage Grafana for customizable, real-time visualizations
- Focus on KPIs, not raw metrics
A good system monitor turns data into insight, not noise.
Security and Compliance Risks
Monitoring tools collect sensitive data, making them targets for attackers.
- Solution: Encrypt data in transit and at rest
- Enforce role-based access control (RBAC)
- Audit logs for monitoring activity
Ensure your system monitor complies with standards like GDPR, HIPAA, or SOC 2.
What is a system monitor?
A system monitor is a software tool that tracks the performance, availability, and health of computer systems, networks, and applications. It collects metrics like CPU usage, memory, disk I/O, and network activity to help IT teams detect issues, prevent outages, and optimize performance.
What are the best open-source system monitor tools?
Top open-source options include Zabbix, Prometheus, and Nagios. Zabbix offers enterprise features with a large community, Prometheus excels in cloud-native environments, and Nagios provides extensive plugin support and customization.
How does a system monitor help with DevOps?
A system monitor enables continuous feedback by providing real-time performance data. This helps DevOps teams detect bugs early, automate responses, ensure service reliability, and maintain high deployment velocity without sacrificing stability.
Can a system monitor predict hardware failures?
Yes, modern system monitors with AI capabilities can analyze trends in disk health, temperature, and usage patterns to predict potential hardware failures before they occur, allowing for proactive maintenance.
Is system monitoring necessary for small businesses?
Absolutely. Even small businesses rely on IT systems for operations. A basic system monitor can prevent downtime, protect data, and ensure smooth customer experiences—often with low-cost or free tools like PRTG or Zabbix.
Choosing the right system monitor is more than just picking a tool—it’s about building a resilient, responsive IT foundation. From open-source stalwarts like Zabbix to AI-powered platforms like Datadog, the options are vast. The key is aligning your choice with your infrastructure, goals, and team capabilities. By tracking critical metrics, leveraging automation, and embracing intelligent alerting, you turn reactive chaos into proactive control. In an era where digital performance defines business success, a powerful system monitor isn’t just a tool—it’s your strategic advantage.
Recommended for you 👇
Further Reading: